Model and describe non-linear relationships
Source:vignettes/describe_nonlinear.Rmd
describe_nonlinear.RmdThis vignette will present how to model and describe non-linear
relationships using estimate. Warning: we will go
full Bayesian. If you’re not familiar with the Bayesian
framework, we recommend starting with this
gentle introduction.
Most of relationships present in nature are non-linear, consisting of quadratic curves or more complex shapes. In spite of that, scientists tend to model data through linear links. Reasons for that include technical and interpretation complexity.
However, advances in software makes modeling of non-linear relationship very straightforward (insert link to future blogpost). Nevertheless, the added cost in terms of interpretation, report and communication often remain a barrier, as the human brain more easily understands linear relationships (e.g., as this variable increases, that variable increases).
The estimate package aims at easing this step by
summarizing non-linear curves in terms of linear
segments.
estimate_smooth
Let’s start by creating a very simple dataset:
data <- data.frame(x = -50:50) # Generate dataframe with one variable x
data$y <- data$x^2 # Add a variable y
data$y <- data$y + rnorm(nrow(data), mean = 0, sd = 100) # Add some gaussian noise
library(ggplot2) # For plotting
library(see) # For nice themes
ggplot(data, aes(x = x, y = y)) +
geom_point() +
see::theme_modern()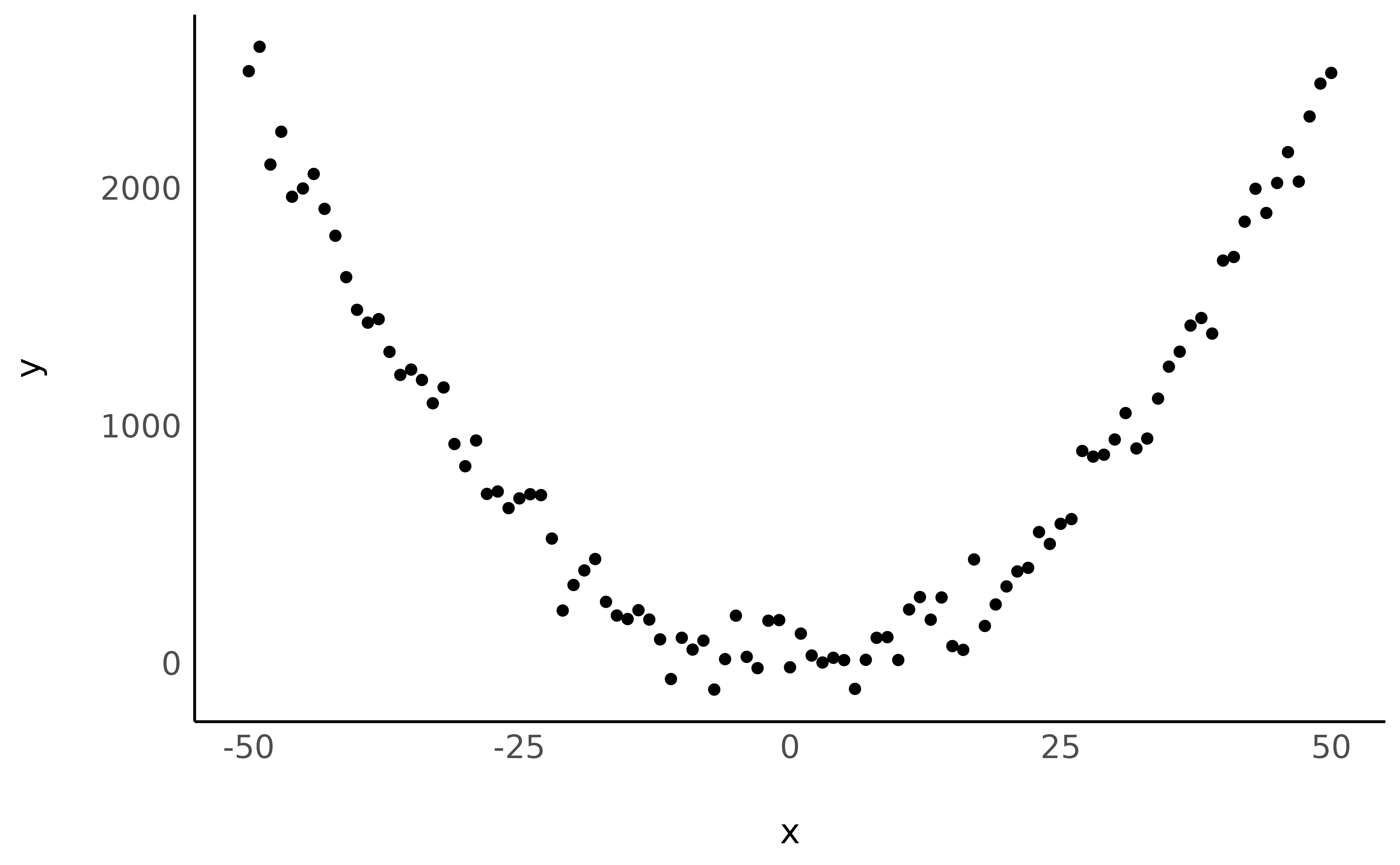
Looking nice! Now let’s model this non-linear relationship using a polynomial term:
Let’s continue with visualising the fitted model:
library(modelbased)
estim <- estimate_relation(model, length = 50)
ggplot(estim, aes(x = x, y = Predicted)) +
geom_line(color = "purple") +
geom_point(data = data, aes(x = x, y = y)) + # Add original data points
see::theme_modern()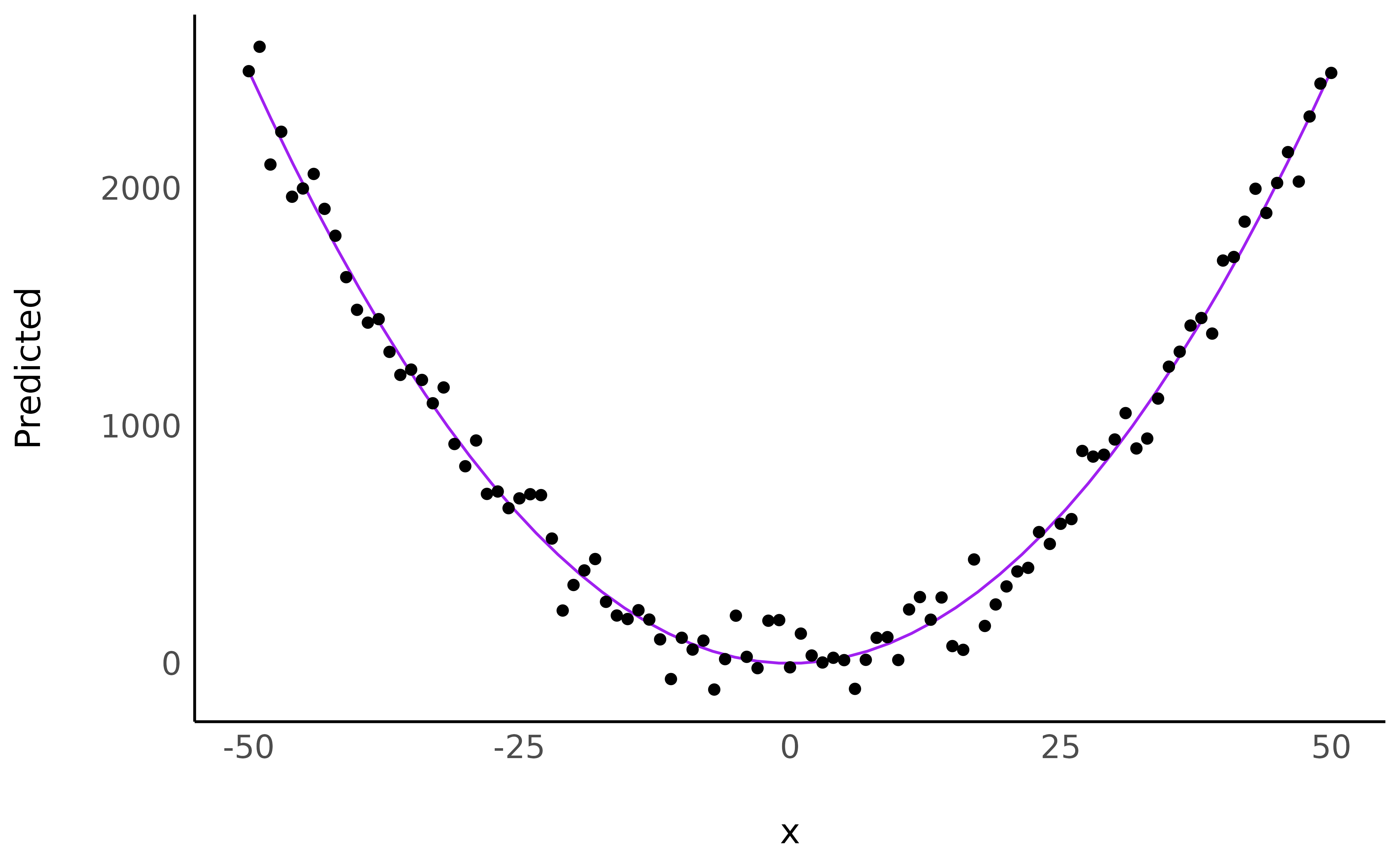
Although a visual representation is usually recommended, how can we verbally describe this relationship?
describe_nonlinear(estim, x = "x", y = "Predicted")> Start | End | Length | Change | Slope | R2
> ------------------------------------------------------
> -50.00 | -1.02 | 0.48 | -2490.97 | -50.86 | 4.90e-07
> -1.02 | 50.00 | 0.50 | 2492.80 | 48.86 | 4.90e-07describe_nonlinear will decompose this curve into linear
parts, returning their size (the percentage of the curve of the
segment), and the trend (positive or negative). We can now say that that
the relationship can be summarised as one negative link and positive
link, with a changing point located roughly around
0.
Real application: Effect of time on memory
We will download and use a dataset where participants had to answer
questions about the movie Avengers: Age of ultron
(combined into a memory score) a few days after
watching it at the theater (the delay variable). Let’s
visualize how the Delay, in days, influences the
Memory score, by plotting the data points and a raw
loess fit on this raw data.
library(datawizard)
library(ggplot2)
library(see)
# Load the data and filter out outliers
df <- read.csv("https://raw.githubusercontent.com/DominiqueMakowski/2017being/master/data/data.csv")
df <- data_filter(df, Delay <= 14 & Memory >= 20)
# Plot the density of the point and a loess smooth line
ggplot(df, aes(x = Delay, y = Memory)) +
stat_density_2d(geom = "raster", aes(fill = after_stat(density)), contour = FALSE) +
geom_jitter(width = 0.2, height = 0.2) +
scale_fill_viridis_c() +
geom_smooth(formula = "y ~ x", method = "loess", color = "red", se = FALSE) +
theme_modern(legend.position = "none")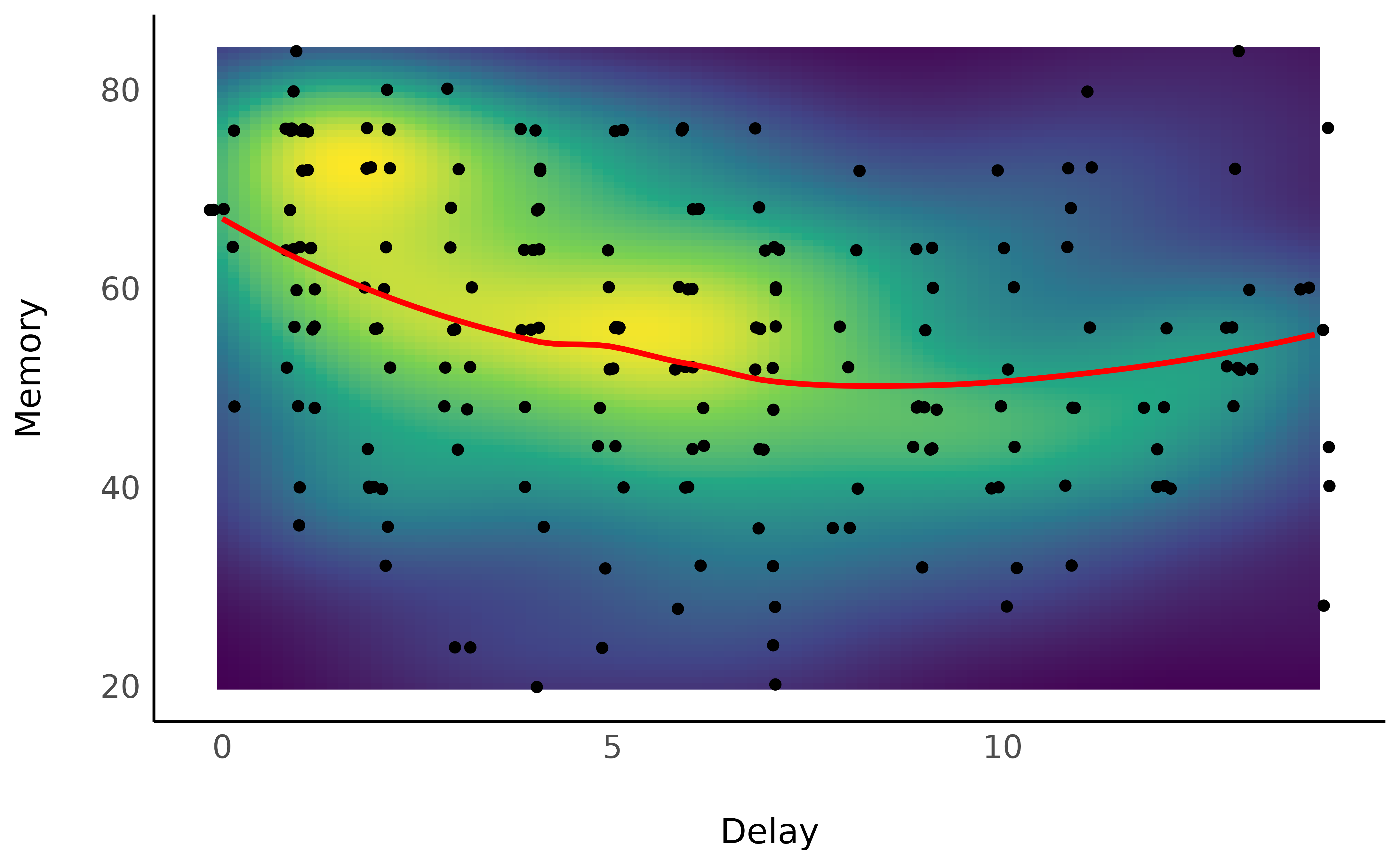
Unsurprisingly, the forgetting curve appears to be non-linear, as supported by the literature suggesting a 2nd order polynomial curve (Averell and Heathcote 2011).
Modelling non-linear curves
We can fit a Bayesian linear mixed regression to model such relationship, adding it a few other variables that could influence this curve, such as the familiarity with the characters of the movie, the language of the movie, the immersion (2D/3D).
library(lme4)
model <- lmer(Memory ~ poly(Delay, 2) * Characters_Familiarity + (1 | Movie_Language) + (1 | Immersion), data = df)We can visualize the link between the Delay and the Memory score by
using the estimate_relation.
library(modelbased)
estim <- estimate_relation(model, by = "Delay", ci = c(0.50, 0.69, 0.89, 0.97))
ggplot(estim, aes(x = Delay, y = Predicted)) +
geom_jitter(data = df, aes(y = Memory), width = 0.2, height = 0.2) +
geom_ribbon(aes(ymin = CI_low_0.97, ymax = CI_high_0.97), alpha = 0.2, fill = "blue") +
geom_ribbon(aes(ymin = CI_low_0.89, ymax = CI_high_0.89), alpha = 0.2, fill = "blue") +
geom_ribbon(aes(ymin = CI_low_0.69, ymax = CI_high_0.69), alpha = 0.2, fill = "blue") +
geom_ribbon(aes(ymin = CI_low_0.5, ymax = CI_high_0.5), alpha = 0.2, fill = "blue") +
geom_line(color = "blue") +
theme_modern(legend.position = "none") +
ylab("Memory")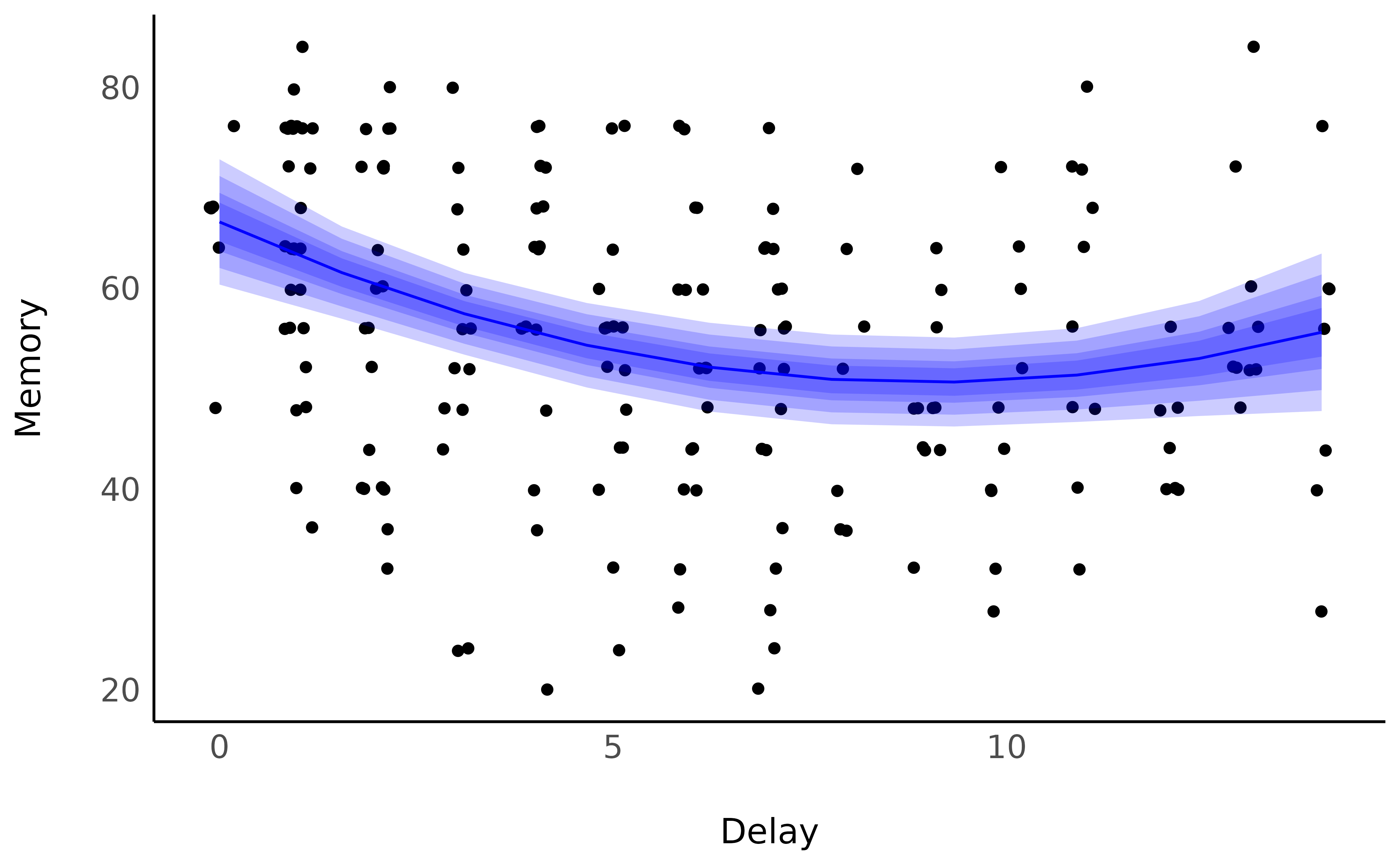
It seems that the memory score starts by decreasing, up to a point where it stabilizes (and even increases, which might be related by some other factors, such as discussions about the movie, watching of YouTube reviews and such). But what is the point of change?
Describing smooth
estimate_smooth(estim, x = "Delay")> Start | End | Length | Change | Slope | R2
> ----------------------------------------------
> 0.00 | 7.78 | 0.53 | -15.68 | -2.02 | 0.50
> 7.78 | 14.00 | 0.37 | 4.69 | 0.75 | 0.50