What is easystats?
easystats is a collection of R packages, which aims to provide a unifying and consistent framework to tame, discipline, and harness the scary R statistics and their pesky models.
However, there is not (yet) an unique “easystats” way of doing data analysis. Instead, start with one package and, when you’ll face a new challenge, do check if there is an easystats answer for it in other packages. You will slowly uncover how using them together facilitates your life. And, who knows, you might even end up using them all.
![]()
Statement of Need
R is a powerful language for statistical computing, but its capabilities are scattered across a fragmented landscape of packages. Conducting a full analysis consisting of data manipulation, modeling, diagnostics, interpretation, and visualization, often requires juggling multiple tools with different syntax, design principles, outputs, and classes. This creates barriers for newcomers and inefficiencies even for experienced users.
The easystats ecosystem addresses this challenge by enabling a seamless workflow from data exploration to result communication, while nudging users toward good, reproducible and transparent statistical practices with sensible defaults and clear documentation. The packages in this ecosystem share consistent syntax and integrate seamlessly, making robust analysis more accessible while reducing cognitive load for novice and experienced R users alike.
The modular and lightweight nature of the easystats ecosystem enables developers to use and integrate in other packages only the necessary components. For example, insight, a dependency-free package for retrieving model information, is utilized by 45 other CRAN packages, such as marginaleffects and gtsummary. In contrast, the easystats meta-package provides users with a cohesive experience, granting access to the entire ecosystem and its consistent design principles without needing to know the specific package of each function.
Installation
![]()
| Type | Source | Command |
|---|---|---|
| Release | CRAN | install.packages("easystats") |
| Development | r-universe | install.packages("easystats", repos = "https://easystats.r-universe.dev") |
| Development | GitHub | remotes::install_github("easystats/easystats") |
Finally, as easystats sometimes depends on some additional packages for specific functions that are not downloaded by default. If you want to benefit from the full easystats experience without any hiccups, simply run the following:
easystats::install_suggested()Citation
To cite the package, run the following command:
citation("easystats")
To cite easystats in publications use:
Lüdecke, Patil, Ben-Shachar, Wiernik, Bacher, Thériault, & Makowski
(2022). easystats: Framework for Easy Statistical Modeling,
Visualization, and Reporting. CRAN.
doi:10.32614/CRAN.package.easystats
<https://doi.org/10.32614/CRAN.package.easystats>
A BibTeX entry for LaTeX users is
@Article{,
title = {easystats: Framework for Easy Statistical Modeling, Visualization, and Reporting},
author = {Daniel Lüdecke and Mattan S. Ben-Shachar and Indrajeet Patil and Brenton M. Wiernik and Etienne Bacher and Rémi Thériault and Dominique Makowski},
journal = {CRAN},
doi = {10.32614/CRAN.package.easystats},
year = {2022},
note = {R package},
url = {https://easystats.github.io/easystats/},
}If you want to do this only for certain packages in the ecosystem, have a look at this article on how you can do so! https://easystats.github.io/easystats/articles/citation.html
Getting started
Each easystats package has a different scope and purpose. This means your best way to start is to explore and pick the one(s) that you feel might be useful to you. However, as they are built with a “bigger picture” in mind, you will realize that using more of them creates a smooth workflow, as these packages are meant to work together. Ideally, these packages work in unison to cover all aspects of statistical analysis and data visualization.
- report: 📜 🎉 Automated statistical reporting of objects in R
- correlation: 🔗 Your all-in-one package to run correlations
- modelbased: 📈 Estimate effects, group averages and contrasts between groups based on statistical models
- bayestestR: 👻 Great for beginners or experts of Bayesian statistics
- effectsize: 🐉 Compute, convert, interpret and work with indices of effect size and standardized parameters
- see: 🎨 The plotting companion to create beautiful results visualizations
- parameters: 📊 Obtain a table containing all information about the parameters of your models
- performance: 💪 Models’ quality and performance metrics (R2, ICC, LOO, AIC, BF, …)
- insight: 🔮 For developers, a package to help you work with different models and packages
- datawizard: 🧙 Magic potions to clean and transform your data
Frequently Asked Questions
How is easystats different from the tidyverse?
You’ve probably already heard about the tidyverse, another very popular collection of packages (ggplot, dplyr, tidyr, …) that also makes using R easier. So, should you pick the tidyverse or easystats? Pick both!
Indeed, these two ecosystems have been designed with very different goals in mind. The tidyverse packages are primarily made to create a new R experience, where data manipulation and exploration is intuitive and consistent. On the other hand, easystats focuses more on the final stretch of the analysis: understanding and interpreting your results and reporting them in a manuscript or a report, while following best practices. You can definitely use the easystats functions in a tidyverse workflow!
easystats + tidyverse = ❤️
Can easystats be useful to advanced users and/or developers?
Yes, definitely! easystats is built in terms of modules that are general enough to be used inside other packages. For instance, the insight package is made to easily implement support for post-processing of pretty much all regression model packages under the sun. We use it in all the easystats packages, but it is also used in other non-easystats packages, such as ggstatsplot, modelsummary, ggeffects, and more.
So why not in yours?
Moreover, the easystats packages are very lightweight, with a minimal set of dependencies, which again makes it great if you want to rely on them.
What are all the packages for? I’m lost!
Statistical models are scary monsters, and easystats is the best solution for expert and amateur stats hunters.
- insight contains the arsenal to capture them and dissect them. It is mostly meant to be used by experts who want to create their own tools.
- performance can be used to assess their scariness and value.
- effectsize is great to quantify and interpret their dangerousness (e.g., by how much variance they eat).
- parameters is useful to understand them by measuring their claws and taming them.
- modelbased allows you to unleash their power and use them at your service.
- datawizard contains useful potions and hunter equipment to survive in the stats jungle.
- bayestestR contains specific arrows and traps for a particular species of monsters (the monstrous Bayesians)
- see allows you to see clearer.
However, easystats can be used as a whole, by simply loading library(easystats) and using the functions from various packages without caring where they belong.
Documentation
Websites
Each easystats package has a dedicated website.
For example, website for parameters is https://easystats.github.io/parameters/.
Blog
In addition to the websites containing documentation for these packages, you can also read posts from easystats blog: https://easystats.github.io/blog/posts/.
Other learning resources
In addition to these websites and blog posts, you can also check out the following presentations and talks to learn more about this ecosystem:
https://easystats.github.io/easystats/articles/resources.html
Dependencies
easystats packages are designed to be lightweight, i.e., they don’t have any third-party hard dependencies, other than base-R packages or other easystats packages! If you develop R packages, this means that you can safely use easystats packages as dependencies in your own packages, without the risk of entering the dependency hell.
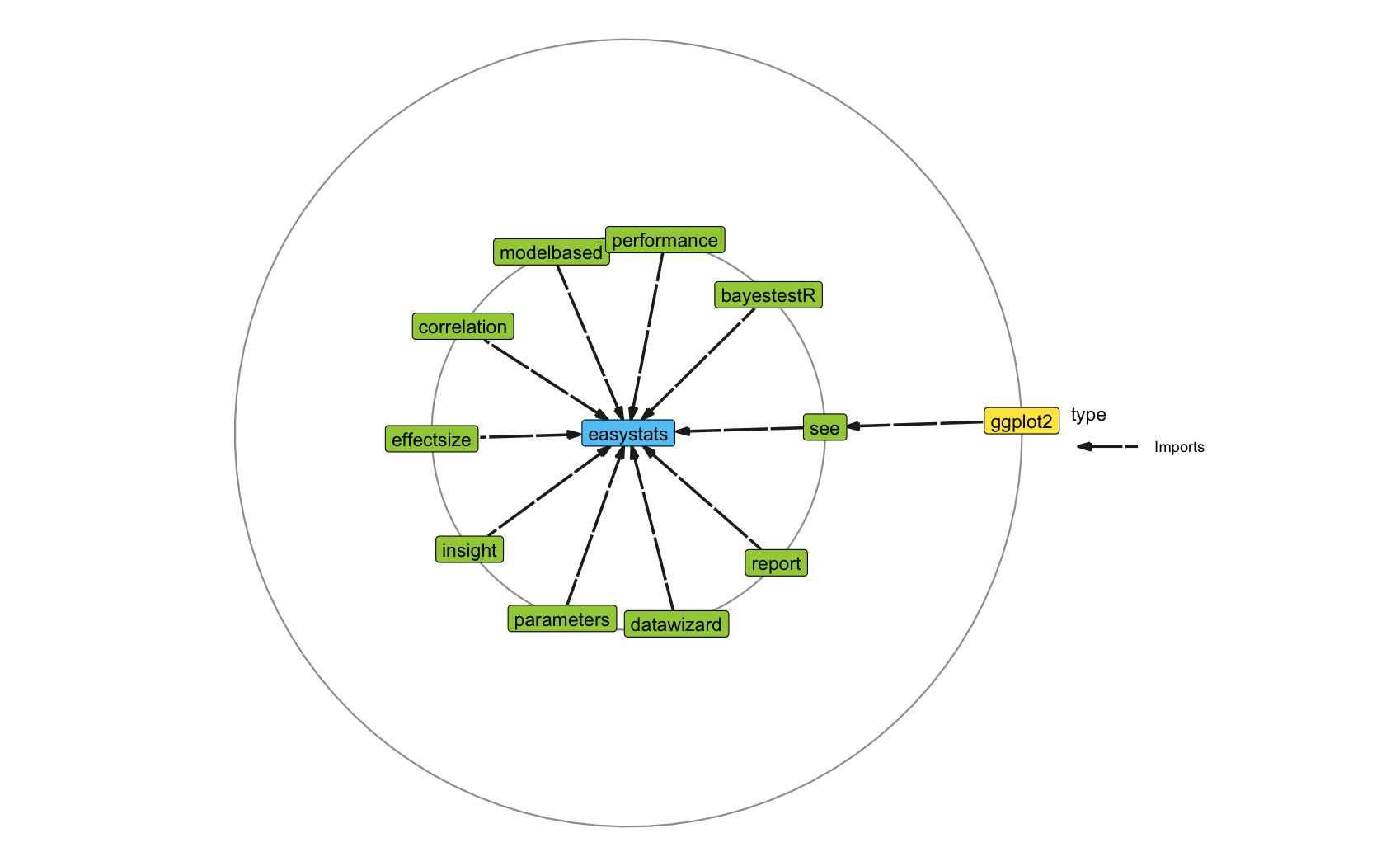
As we can see, the only exception is the {see} package, which is responsible for plotting and creating figures and relies on ggplot2, which does have a substantial number of dependencies.
Usage
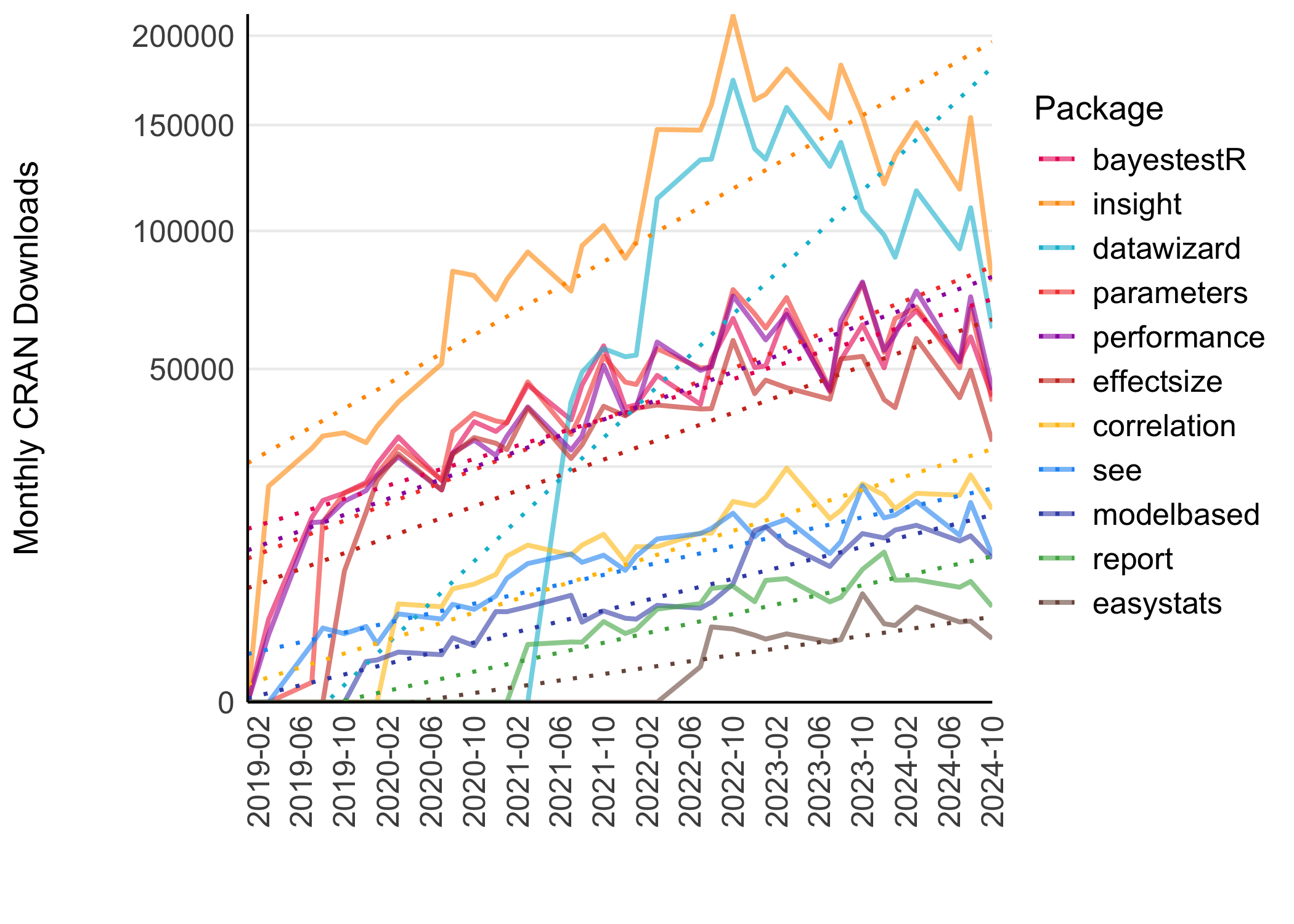
Downloads
Download statistics for easystats packages from CRAN.
| Package | Total | Monthly |
|---|---|---|
| insight | 10,677,902 | 122,735 |
| datawizard | 7,141,788 | 119,030 |
| performance | 4,866,306 | 56,585 |
| parameters | 4,712,565 | 57,470 |
| bayestestR | 4,654,097 | 54,117 |
| effectsize | 3,491,678 | 44,198 |
| correlation | 1,316,058 | 17,547 |
| see | 1,066,925 | 12,552 |
| modelbased | 785,365 | 10,200 |
| report | 399,267 | 6,440 |
| easystats | 182,224 | 3,961 |
| Total | 39,294,175 | 504,835 |
Citations
Number of Google Scholar citations for easystats publications.
easystats::easystats_citations(sort_by = "cites")| Title | Journal | Year | Cites |
|---|---|---|---|
| performance: An R package for assessment,… | Journal of Open Source Software | 2021 | 7,149 |
| effectsize: Estimation of effect size indices and… | Journal of open source software | 2020 | 2,503 |
| bayestestR: Describing Effects and their… | Journal of Open Source Software | 2019 | 1,870 |
| Indices of Effect Existence and Significance in… | Frontiers in Psychology | 2019 | 1,118 |
| Methods and algorithms for correlation analysis in… | Journal of Open Source Software | 2020 | 940 |
| Extracting, computing and exploring the parameters… | Journal of Open Source Software | 2020 | 649 |
| see: An R package for visualizing statistical… | Journal of Open Source Software | 2021 | 171 |
| insight: A Unified Interface to Access Information… | Journal of Open Source Software | 2019 | 160 |
| The {easystats} collection of R packages | GitHub | 2020 | 155 |
| modelbased: An R package to make the most out of… | Journal of Open Source Software | 2025 | 144 |
| The report package for R: ensuring the use of best… | CRAN | 2019 | 74 |
| datawizard: An R package for easy data preparation… | Journal of Open Source Software | 2022 | 72 |
| Phi, Fei, Fo, Fum: effect sizes for categorical… | Mathematics | 2023 | 70 |
| Check your outliers! An introduction to… | Behavior Research Methods | 2024 | 67 |
| Choosing informative priors in Bayesian regression… | 2025 | 0 | |
| Total | 15,142 |
Contributing
We are happy to receive bug reports, suggestions, questions, and (most of all) contributions to fix problems and add features. Pull Requests for contributions are encouraged.
Here are some simple ways in which you can contribute (in the increasing order of commitment):
- Read and correct any inconsistencies in the documentation
- Raise issues about bugs or wanted features
- Review code
- Add new functionality
Code of Conduct
Please note that the ‘easystats’ project is released with a Contributor Code of Conduct. By contributing to this project, you agree to abide by its terms.